
Strata Summit 2011: Generating Stories From Data [VIDEO]
As the world of data expands, new challenges arise. The complexity of some datasets can be overwhelming for journalists across the globe who “dig” for a story without the technical skills. Narrative Science’s Kristian Hammond addressed this challenge during last week’s Strata Summit in New York in a presentation about a software platform that helps write stories out of numbers…
[youtube P9hJJCOeIB4]
Strata Summit 2011: The US Government’s Big Data Opportunity [VIDEO]
So the Strata Summit happened last week and blew our data minds with new ideas and incredible speeches from the best people in the data world. One of the highlights we particularly liked was the conversation about the future of open government data in the US.
Here is a video where Aneesh Chopra, the US Federal Chief Technology Officer, deputy CTO Chris Vein, and Tim O’Reilly, founder and CEO of O’Reilly Media, discuss Obama’s latest visit to New York and the opportunities that big datasets could set for the future…
[youtube 4wdkk9B7qec]
More info on the speakers (from O’Reilly website):

Aneesh Chopra
Federal Office of Science and Technology Policy
Chopra serves as the Federal Chief Technology Officer. In this role, Chopra promotes technological innovation to help the country meet its goals from job creation, to reducing health-care costs, to protecting the homeland. Prior to his confirmation, he served as Virginia’s Secretary of Technology. He lead the Commonwealth’s strategy to effectively leverage technology in government reform, to promote Virginia’s innovation agenda, and to foster technology-related economic development. Previously, he worked as Managing Director with the Advisory Board Company, leading the firm’s Financial Leadership Council and the Working Council for Health Plan Executives.

Chris Vein
Office of Science and Technology Policy
Chris Vein is the Deputy U.S. Chief Technology Officer for Government Innovation in the White House Office of Science and Technology Policy. In this role, Chris searches for those with transformative ideas, convenes those inside and outside government to explore and test them, and catalyzes the results into a national action plan. .Prior to joining the White House, Chris was the Chief Information Officer (CIO) for the City and County of San Francisco (City) where he led the City in becoming a national force in the application of new media platforms, use of open source applications, creation of new models for expanding digital inclusion, emphasizing “green” technology, and transforming government. This year, Chris was again named to the top 50 public sector CIOs by InformationWeek Magazine. He has been named to Government Technology Magazine’s Top 25: Dreamers, Doers, and Drivers and honored as the Community Broadband Visionary of the Year by the National Association of Telecommunications Officers and Advisors (NATOA). Chris is a sought-after commentator and speaker, quoted in a wide range of news sources from the Economist to Inc. Magazine. In past work lives, Chris has worked in the public sector at Science Applications International Corporation (SAIC), for the American Psychological Association, and in a nonpolitical role, at the White House supporting three Presidents of the United States.

Tim O’Reilly
O’Reilly Media, Inc.
Tim O’Reilly is the founder and CEO of O’Reilly Media, Inc., thought by many to be the best computer book publisher in the world. O’Reilly Media also hosts conferences on technology topics, including the O’Reilly Open Source Convention, the Web 2.0 Summit, Strata: The Business of Data, and many others. O’Reilly’s Make: magazine and Maker Faire has been compared to the West Coast Computer Faire, which launched the personal computer revolution. Tim’s blog, O’Reilly Radar, “watches the alpha geeks” to determine emerging technology trends, and serves as a platform for advocacy about issues of importance to the technical community. Tim is also a partner atO’Reilly AlphaTech Ventures, O’Reilly’s early stage venture firm, and is on the board of Safari Books Online.
Data-Driven Journalism At The Guardian [VIDEO]
O’REILLY STRATA SUMMIT
[youtube kTmJIUcoI0c]
Simon Rogers (Guardian)
Talk
Location: Westside Ballroom
Location: Westside Ballroom
Data increasingly drives news reporting, and the Guardian has been at the front of this change. Simon Rogers, editor of the Guardian’s award-winning Datablog, will talk about how data is directing its coverage.
Training data driven journalism: Mind the gaps
Data Driven Journalism – original post can be found here
Editor’s note
Between April and August 2011 the European Journalism Centre (EJC) circulated a survey on training needs for data journalism. We asked two members of our Editorial Board, experts in data journalism, journalist and trainer Mirko Lorenz, and journalism professor and trainer Paul Bradshaw, to analyse the results and share their insights with us. This article is an analysis of the survey results by Mirko Lorenz. On Thursday we will publish the analysis of the survey results by Paul Bradshaw. This second article in the series will be accompanied by the survey data.
Competency with numbers and statistics is a promising field. The assumption is that this competency would enable journalism to gain a greater level of depth and accuracy. But what are the training needs? How can we make this happen? The results of a survey ran by the European Journalism Centre provide some insights into this. Judging from the results of this survey, here is a run-down of the opportunities and challenges that lie ahead.
Data driven journalism on the rise
For the last two years there has been a growing interest in data driven journalism. The Guardian, The New York Times, The Texas Tribune, and The Los Angeles Times are now presenting new ways to look at data from different angles. This adds more clarity and often creates surprises. As a result these offerings are becoming increasingly popular, especially when there is chance to access raw data.
There are many unsolved questions however, regarding data analysis. How can journalists make better use of the numbers, avoid the frequent misinterpretation of statistics, check the reliability of the collected data, and present the facts in a simple yet accurate way in order to overcome pressing problems?
Results from the EJC survey on training needs for data journalism
In an attempt to discover better and more effective ways of training, the European Journalism Centre conducted a survey that ran from April to August. Roughly 200 journalists participated and about 134 of the total number of surveys were fully completed. After much anticipation, the results are finally in.
Subjects who took the survey were in some way familiar with the field of data journalism. Thus we can make no claims for representativeness. Nor are these insights sufficient for designing a training session that fully covers all aspects of data journalism. The answers to the 26 questions of the survey, however, will help you get a better grip on the sentiment, expectations and concerns that are out there.
Selected findings
Here is a brief list of the findings, based on the answers to the survey questions:
1. Opportunity
There is a growing group of journalists who are highly interested in further investigation of datasets. This opportunity of using new sources and new tools is like shining a light into the black boxes that surround us. Or, as a respondent put it: ‘Data can offer insights that contradict popular presumptions’.

2. Motivation
The argument as to what should be learned in order to be a good data journalist varies wildly. Some say that the future journalist should be a researcher, programmer, and designer, thus packing three university degrees into one. Judging from conversations and comments this is a scary perspective for many journalists. Gradually though, this ‘super-expert’ model is being brought down. One reason is because the use of the tools is getting easier. The barrier to coding is lowering and the techniques to write a few lines of code are becoming less complex. Another development is that by learning from good examples of data journalism one can tell that diligence, persistence and creative thinking are probably as important as formal knowledge.
3. Use of data
What are the expectations? The journalists who participated see several ways of how data can be used. Firstly, they want to use data more to provide context, background and perspective. Secondly, they want to dig into the reliability of public claims – are they true, yes or no? What comes out as positive is that data journalism is more than just adding colourful pictures to a story. It allows for new perspectives to be uncovered thus giving more depth and shape to the overall picture.

4. Training needs
Where do journalists need support? What is interesting about the answers is that journalists effectively call for a systematic approach illustrating that how to analyse and how to visualise data are in high demand. Other actions, such as how to search and how to check reliability are viewed as important as well. Learning how to programme is notably low ranked…

5. Practical use
Seeing the potential of what datasets could do for newsrooms, it is clear that there is a demand for personal skills. Journalists want to be able to work with data themselves. While there should be experts available, they should assist existing staff and not keep their knowledge to themselves.

6. Barriers
Working on deadlines does not leave that much room to sit down and tinker with data for hours and days. But while lack of time was cited as one barrier to adopting data journalism, the more important barrier was clearly lack of knowledge. In combination with lack of resources and management support one can see why data journalism could benefit from systematic training.

Conclusion: Mind the gaps
Combining the sentiment from the survey with my own experience in preparing training modules for data driven journalism, the current challenge can be boiled down to three words: Mind the gaps.
1. Systematic approach needed: Misinterpretation of numbers and statistics is pretty common and journalists are quite often part of the problem. Wrongly extrapolating trends, misinterpretation of complex developments and lacking information are often encountered mistakes in journalistic discourse.
So, trainers and institutions in this field should be careful not to skip the very basics when working with numbers and statistics. There is a need for diligence and accuracy, not for bigger pictures.
2. Everybody, please move: Journalists have to learn, but publishers have to do their share too. Working with data can bring in new opportunities for publications, whether in pure print or multiple channels. Data, numbers, facts and context can create a solid base, if used correctly. Today the use of numbers often leads to sensationalism. Journalists sometimes add confusion when they do not take the time to investigate the data. While this may not be correct, it makes sense as long as the media remains mainly in the attention-getting business. But getting attention is no longer an exclusive product of media. There are many different channels that people can use to get their information. I would argue that today the scarce resource is trust. Data journalism used wrongly will only amplify attention for a short time and might have a reverse effect should it become clear that the analysis was faulty.
3. Do not mix three professions into one: It is true that the pioneers of data journalism often possess remarkable skills. They are journalists who know how to write code and produce webpages. Most of them trained themselves, driven by a curiosity to visualise unwieldy data in new ways. As things begin to move forward however, the idea of letting everyone do what they are best at might yield bigger gains. Does this mean journalists will be the facilitators of the process, asking questions and searching for data? Yes. Will these same journalists be tinkering with their publications content management system and producing jaw-dropping visuals just in time? Not likely. As data driven journalism moves on, there should be teams. The idea behind this being that a talented designer would assist the journalists in incorporating data into stories in a quick and improved manner.
These processes are still underway and the picture is incomplete at best. But the prospects are still enticing. What are your thoughts? Let us know.
Resources:
- Slides from presentation of preliminary results of EJC survey on training needs for data journalism
Dutch regional newspapers launch data journalism project RegioHack

In a guest post for OJB, Jerry Vermanen explains the background to RegioHack
The internet is bursting with information, but journalists – at least in The Netherlands – don’t get the full potential out of it. Basic questions on what data driven journalism is, and how to practise it, still have to be answered. Two Dutch regional newspapers (de Stentor and TC Tubantia) have launchedRegioHack, an experiment with data driven journalism around local issues and open data.
Both newspapers circulate in the eastern and middle part of the Netherlands. In November, journalists will collaborate with local students, programmers and open data experts in a 30 hour coding event. In preparation for this hackathon, the forum on our website (www.regiohack.nl) is opened for discussion. Anyone can start a thread for a specific problem. For example, what’s the average age of each town in our region? And in 10 years, do we have enough facilities to accommodate the future population? And if not, what do we need?
The newspapers provide the participants with hot pizza, energy drink and 30 hours to find, clean up and present the data on these subjects. [Read more…]
The work of data journalism: Find, clean, analyze, create … repeat
O’REILLY RADAR – By Mac Slocum
Data journalism has rounded an important corner: The discussion is no longer if it should be done, but rather how journalists can find and extract stories from datasets.
Of course, a dedicated focus on the “how” doesn’t guarantee execution. Stories don’t magically float out of spreadsheets, and data rarely arrives in a pristine form. Data journalism — like all journalism — requires a lot of grunt work.
With that in mind, I got in touch with Simon Rogers, editor of The Guardian’s Datablog and a speaker at next week’s Strata Summit, to discuss the nuts and bolts of data journalism. The Guardian has been at the forefront of data-driven storytelling, so its process warrants attention — and perhaps even full-fledged duplication.
Our interview follows.
What’s involved in creating a data-centric story?
 Simon Rogers: It’s really 90% perspiration. There’s a whole process to making the data work and getting to a position where you can get stories out of it. It goes like this:
Simon Rogers: It’s really 90% perspiration. There’s a whole process to making the data work and getting to a position where you can get stories out of it. It goes like this:
- We locate the data or receive it from a variety of sources — from breaking news stories, government data, journalists’ research and so on.
- We then start looking at what we can do with the data. Do we need to mash it up with another dataset? How can we show changes over time?
- Spreadsheets often have to be seriously tidied up — all those extraneous columns and weirdly merged cells really don’t help. And that’s assuming it’s not a PDF, the worst format for data known to humankind.
- Now we’re getting there. Next up we can actually start to perform the calculations that will tell us if there’s a story or not.
- At the end of that process is the output. Will it be a story or a graphic or a visualisation? What tools will we use?
We’ve actually produced a graphic (of how we make graphics) that shows the process we go through:
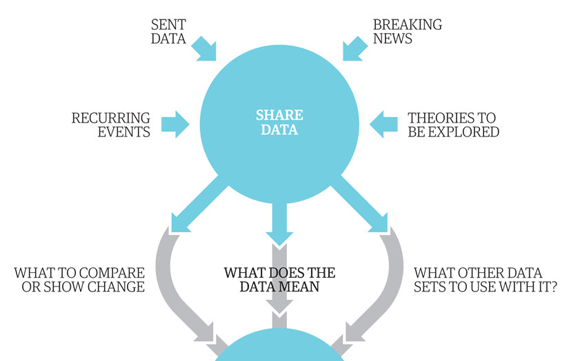
Partial screenshot of “Data journalism broken down.” Click to see the full graphic.
What is the most common mistake data journalists make?
Simon Rogers: There’s a tendency to spend months fiddling around [Read more…]
A GUIDE TO LIBYA’S SURVEILLANCE NETWORK
OWNI.eu – By Jean Marc Manach
After repeated interrogations lead by Reflets.info, OWNI, the Wall Street Journal and the Figaro, Amesys, the French company that sold Internet surveillance systems to Gaddafi’s Libya tried to calm things down with a statement posted on its website (mirror):
The contract only concerned the sale of materials capable of analysing a fraction of existing internet connections, only a few thousand.
However, the documents in OWNI’s possession tell a different story, in fact, the exact opposite story. In contrast to traditional surveillance systems that target specific connections, the “massive” (sic) Amesys surveillance system is used to intercept and analyze the entirety of the telecommunications network, to the scale of an entire country.
In its presentations for the high-end surveillance service, Amesys flaunts EAGLE as having been conceived to monitor the whole spectrum of telecommunications: IP traffic (internet), mobile and landline telephone networks, WiFi, satellite, radio and micro waves thanks to its “passive waves, invisible and inaccessible to any intruder.”
The massive system (EAGLE GLINT, GLobal INTelligence, which was the system sold to Libya), was conceived to respond to interception and surveillance needs at a national level and to be capable of aggregating all kinds of information and analyzing, in real time, a national data flow, from a few terabytes to a few dozens petabytes [1peta-octet = 1024 tera-octets, 1 tera-octet = 1024 giga octets and that the total amount of everything ever written by the human race in all languages is estimated at 50 peta-octets…]


EAGLE is therefore able to aggregate, in an automatic fashion, email and physical addresses, telephone numbers, photos of suspects, but also to make automatic searches by date, hour, telephone number, email address, keyword, localization… [Read more…]
Data-Driven Journalism In A Box: what do you think needs to be in it?
The following post is from Liliana Bounegru (European Journalism Centre), Jonathan Gray (Open Knowledge Foundation), and Michelle Thorne (Mozilla), who are planning a Data-Driven Journalism in a Box session at the Mozilla Festival 2011, which we recently blogged about here. This is cross posted at DataDrivenJournalism.net and on the Mozilla Festival Blog.
We’re currently organising a session on Data-Driven Journalism in a Box at the Mozilla Festival 2011, and we want your input!

In particular:
- What skills and tools are needed for data-driven journalism?
- What is missing from existing tools and documentation?
If you’re interested in the idea, please come and say hello on our data-driven-journalism mailing list!
Following is a brief outline of our plans so far…
What is it?
The last decade has seen an explosion of publicly available data sources – from government databases, to data from NGOs and companies, to large collections of newsworthy documents. There is an increasing pressure for journalists to be equipped with tools and skills to be able to bring value from these data sources to the newsroom and to their readers.
But where can you start? How do you know what tools are available, and what those tools are capable of? How can you harness external expertise to help to make sense of complex or esoteric data sources? How can you take data-driven journalism into your own hands and explore this promising, yet often daunting, new field?
A group of journalists, developers, and data geeks want to compile a Data-Driven Journalism In A Box, a user-friendly kit that includes the most essential tools and tips for data. What is needed to find, clean, sort, create, and visualize data — and ultimately produce a story out of data?
There are many tools and resources already out there, but we want to bring them together into one easy-to-use, neatly packaged kit, specifically catered to the needs of journalists and news organisations. We also want to draw attention to missing pieces and encourage sprints to fill in the gaps as well as tighten documentation.
What’s needed in the Box?
- Introduction
- What is data?
- What is data-driven journalism?
- Different approaches: Journalist coders vs. Teams of hacks & hackers vs. Geeks for hire
- Investigative journalism vs. online eye candy
- Understanding/interpreting data:
- Analysis: resources on statistics, university course material, etc. (OER)
- Visualization tools & guidelines – Tufte 101, bubbles or graphs?
- Acquiring data
- Guide to data sources
- Methods for collecting your own data
- FOI / open data
- Scraping
- Working with data
- Guide to tools for non-technical people
- Cleaning
- Publishing data
- Rights clearance
- How to publish data openly.
- Feedback loop on correcting, annotating, adding to data
- How to integrate data story with existing content management systems
What bits are already out there?
- Open Data Manual
- Data Patterns
- Data Journalism Manual
- List(s) of Free/Open Tools for working with data
- Data Journalism Developer Studio
What bits are missing?
- Tools that are shaped to newsroom use
- Guide to browser plugins
- Guide to web-based tools
Opportunities with Data-Driven Journalism:
- Reduce costs and time by building on existing data sources, tools, and expertise.
- Harness external expertise more effectively
- Towards more trust and accountability of journalistic outputs by publishing supporting data with stories. Towards a “scientific journalism” approach that appreciates transparent, empirically- backed sources.
- News outlets can find their own story leads rather than relying on press releases
- Increased autonomy when journalists can produce their own datasets
- Local media can better shape and inform media campaigns. Information can be tailored to local audiences (hyperlocal journalism)
- Increase traffic by making sense of complex stories with visuals.
- Interactive data visualizations allow users to see the big picture & zoom in to find information relevant to them
- Improved literacy. Better understanding of statistics, datasets, how data is obtained & presented.
- Towards employable skills.
Keen On… Michael Fertik: Why Data is the New Oil and Why We, the Consumer, Aren’t Benefitting From It
TECH CRUNCH – By Andrew Keen
As he told me when he came into our San Francisco studio earlier this week,Reputation.com CEO & Founder Michael Fertik is “ecstatic” about our new reputation economy. In today’s Web 3.0 personal data rich economy, reputation is replacing cash, Fertik believes. And he is confident that his company, Reputation.com, is well placed to become the new rating index of this digital ecosystem.
But Fertik isn’t ecstatic about the way in which new online products, such as facial recognition technology, are exploiting the privacy of online consumers. Arguing that “data is the new oil,” Fertik believes that the only people not benefitting from today’s social economy are consumers themselves. Rather than government legislation, however, the solution, Fertik told me, are more start-up entrepreneurs like himself providing paid products that empower consumers in our Web 3.0 world of pervasive personalized data.
This is the second and final part of my interview with Fertik. Yesterday, he explained to me why people will pay for privacy.
Why data is the new oil
[youtube xgvEp0CWKjw]