DATA MINER UK – by Nicola Hughes
Such a great article on the story of data journalism by Nicola Hughes that we decided to put it all! Get the original article on Data Miner UK…
[youtube 3YcZ3Zqk0a8]
And here’s what Tim Berner-Lee, founder of the internet, said regarding the subject of data journalism:
Journalists need to be data-savvy… [it’s] going to be about poring over data and equipping yourself with the tools to analyse it and picking out what’s interesting. And keeping it in perspective, helping people out by really seeing where it all fits together, and what’s going on in the country
How the Media Handle Data:
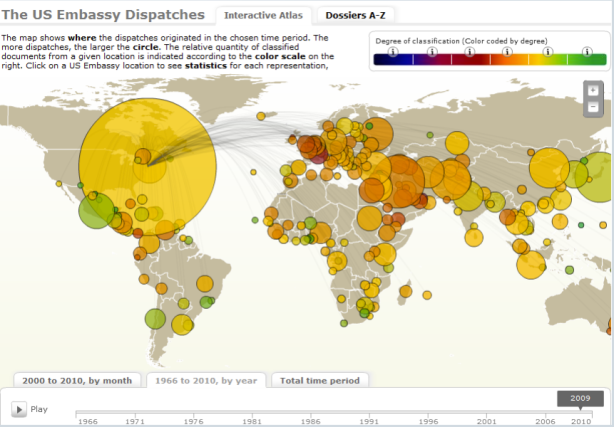
Data has sprung onto the journalistic platform of late in the form of the Iraq War Logs (mapped by The Guardian), the MP’s expenses (bought by The Telegraph) and the leaked US Embassy Cables (visualized by Der Spiegel). What strikes me about these big hitters is the existence of the data is a story in itself. Which is why they had to be covered. And how they can be sold to an editor. These data events force the journalistic platform into handling large amounts of data. The leaks are stories so there’s your headline before you start actually looking for stories. In fact, the Fleet Street Blues blog pointed out the sorry lack of stories from such a rich source of data, noting the quick turn to headlines about Wikileaks and Assange.
Der Spiegel – The US Embassy Dispatches
So journalism so far has had to handle large data dumps which has spurred on the area of data journalism. But they also serve to highlight the fact that the journalistic platform as yet cannot handle data. Not the steady stream of public data eking out of government offices and public bodies. What has caught the attention of news organizations is social media. And that’s a steady stream of useful information. But again, all that’s permitted is some fancy graphics hammered out by programmers who are glad to be dealing with something more challenging than picture galleries (here’s an example of how CNN used twitter data).
So infographics (see the Stanford project: Journalism in the Age of Data) and interactives (e.g. New York Times: A Peek into Netflix Queues) have been the keystone from which the journalism data platform is being built. But there are stories and not just pictures to be found in data. There are strange goings-on that need to be unearthed. And there are players outside of the newsroom doing just that.
How the Data Journalists Handle Data:
Data, before it was made sociable or leakable, was the beat of the computer-assisted-reporters (CAR). They date as far back as 1989 with the setting up of the National Institute for Computer-Assisted Reporting in the States. Which is soon to be followed by the European Centre for Computer Assisted Reporting. The french group, OWNI, are the latest (and coolest) revolutionaries when it comes to new age journalism and are exploring the data avenues with aplomb. CAR then morphed into Hacks/Hackers when reporters realized that computers were tools that every journalist should use for reporting. There’s no such thing as telephone-assisted-reporting. So some whacky journalists (myself now included) decided to pair up with developers to see what can be done with web data.

This now seems to be catching on in the newsroom. The Chicago Tribune has a data center, to name just one. In fact, the data center at the Texas Tribune drives the majority of the sites traffic. Data journalism is growing alongside the growing availability of data and the tools that can be used to extract, refine and probe it. However, at the core of any data driven story is the journalist. And what needs to be fostered now, I would argue, is the data nose of a (any) journalist. Journalism, in its purest form, is interrogation. The world of data is an untapped goldmine and what’s lacking now is the data acumen to get digging. There are Pulitzers embedded in the data strata which can be struck with little use of heavy machinery. Data driven journalism and indeed CAR has been around long before social media, web 2.0 and even the internet. One of the earliest examples of computer assisted reporting was in 1967, after riots in Detroit, when Philip Meyer used survey research, analyzed on a mainframe computer, to show that people who had attended college were equally likely to have rioted as were high school dropouts. This turned the publics’ attention to the pervasive racial discrimination in policing and housing in Detroit.
Where Data Fits into Journalism:
I’ve been looking at the States and the broadsheets reputation for investigative journalism has produced some real gems. What stuck me, by looking at news data over the Atlantic, is that data journalism has been seeded earlier and possibly more prolifically than in the UK. I’m not sure if it’s more established but I suspect so (but not by a wide margin). For example, at the end of 2004, the then Dallas Morning News analyzed the school test scores of the Texas Assessment of Knowledge and Skills and uncovered one school’s alleged cheating on standardized tests. This then turned into a story on cheating across the state. The Seattle Times piece of 2008, logging and landslides, revealed how a logging company was blatantly allowed to clear-cut unstable slopes. Not only did they produce and interactive but the beauty of data journalism (which is becoming a trend) is to write about how the investigation was uncovered using the requested data.

The Seattle Times: Landslides in the Upper Chehalis River Basin
Newspapers in the US are clearly beginning to realize that data is a commodity for which you can buy trust from your consumer. The need for speed seems to be diminishing as social media gets there first, and viewers turn to the web for richer information. News in the sense of something new to you, is being condensed into 140 character alerts, newsletters, status updates and things that go bing on your mobile device. News companies are starting to think about news online as exploratory information that speaks to the individual (which is web 2.0). So the The New York Times has mapped the census data in its project “Mapping America: Every City, Every Block”. The Los Angeles Times has also added crime data so that its readers are informed citizens not just site surfers. My personal heros are the investigative reporters at ProPublica who not only partner with mainstream news outlets for projects like Dollars for Doctors, they also blog about the new tools they’re using to dig the data. Proof the US is heading down the data mine is the fact that Pulitzer finalists for local journalism included a two year data dig by the Las Vegas Sun into preventable medical mistakes in Las Vegas hospitals.
Lessons in Data Journalism:
Another sign that data journalism is on the up is the recent uptake at teaching centres for the next generation journalist. Here in the UK, City University has introduced an MA in Interactive Journalism which includes a module in data journalism. Across the pond, the US is again ahead of the game with Columbia University offering a duel masters’ in Computer Science and Journalism. Words from the journalism underground are now muttering terms like Goolge Refine, Ruby and Scraperwiki. O’Reilly Radar has talked about data journalism.
The beauty of the social and semantic web is that I can learn from the journalists working with data, the miners carving out the pathways I intend to follow. They share what they do. Big shot correspondents get a blog on the news site. Data journalists don’t, but they blog because they know that collaboration and information is the key to selling what it is they do (e.g Anthony DeBarros, database editor at USA Today). They are still trying to sell damned good journalism to the media sector! Multimedia journalists for local news are getting it (e.g David Higgerson, Trinity Mirror Regionals). Even grassroots community bloggers are at it (e.g. Joseph Stashko of Blog Preston). Looks like data journalism is working its way from the bottom up.
Back in Business:
Here are two interesting articles relating to the growing area of data and data journalism as a business. Please have a look: Data is the New Oil and News organizations must become hubs of trusted data in a market seeking (and valuing) trust.